What if all words were computed equal?
Experiences with Data Science interviews made me realise that, to solve problems you do not know the answer to, it helps to start laying out what you already know and thinking out loud.
I had this realisation in the midst of rapid development and release of reasoning AI models like OpenAI’s o1 and DeepSeek R1.
I could not help seeing the parallel between the two; a parallel that I will explore today.
If you are a Data Science/Maths-inclined reader, expand this to read about the exact question and my thinking process
Given two normally distributed random variables: \(X \sim N(0,1)\) and \(Y \sim N(0,1)\)
What is the probability of \(X - 3Y > 0\)?
I started by drawing a bell curve and reminding myself and my interviewers that normal distributions are symmetrical.
I also stated that the distribution of a third variable \(Z = X - 3Y\) should also be symmetrical, as:
- \(3Y\) is normally distributed, centred around 0
- \(X\) is normally distributed, centred around 0
Then, the sum of these two distributions must also be normally distributed, centred around 0, and therefore, symmetrical around 0.
This would mean that the probability of \(Z > 0\) is exactly \(0.5\).
I would not have come up with this solution had I not reminded myself early on of the “evident” fact that normal distributions are symmetrical.
In solving a range of other tough problems at work and teaching, I find it useful to state intuitions early on. These signals can always be building blocks of a more sophisticated solution.
Predicting the next word and reasoning
When predicting the next word in a sentence, such as:
The capital of France is (?)We do not need to think too much. We can easily come up with “Paris”.
Predicting some other words may require some more thinking.
For instance:
I have three cards:
- black-black: black on both sides
- white-white: white on both sides
- white-black: black on one side and white on the other
I pick one card at random, its first side is white.
The probability that its other side is white is (?)There, we may need some more thinking time, even though the task we are doing is still predicting the next word in the sentence. I would recommend taking a second to try figuring this one out.
Expand to find the answer to the problem (Spoilers: it is not \(1/2\))
We try to solve the problem: given that the first side of the card is white, what is the probability that the other is white?
Our intuition may lead us to say \(1/2\), as there are two cards with a white side: one with two white sides, the other with one black and one white side. From this observation, it would make sense to say that if the first side is white, then the probability of the other side being white is \(1/2\).
This reasoning is unfortunately flawed; the correct answer is \(2/3\).
If you do not believe me, you can run this simulation in Python and check the results:
Python code simulation
import random
trials = 100000
cards = ["white-white", "white-black", "black-black"]
white_first_count = 0
white_white_count = 0
for _ in range(trials):
card = random.choice(cards)
if card == "white-white":
white_first_count += 1
white_white_count += 1
elif card == "white-black":
if random.choice(["white", "black"]) == "white":
white_first_count += 1
probability = white_white_count / white_first_count if white_first_count > 0 else 0
print(f"Probability of the other side being white: {probability}")To understand why this reasoning is flawed, it is important to remember how a white side could have been drawn:
- The white-white card could have been drawn on one of its sides
- The white-white card could have been drawn on its other side
- The black-white card could have been drawn on its white side
From this observation, we can see that of the situations that lead us to the first side of the card being white, 2 out of 3 were with the white-white card.
This can also be shown visually:
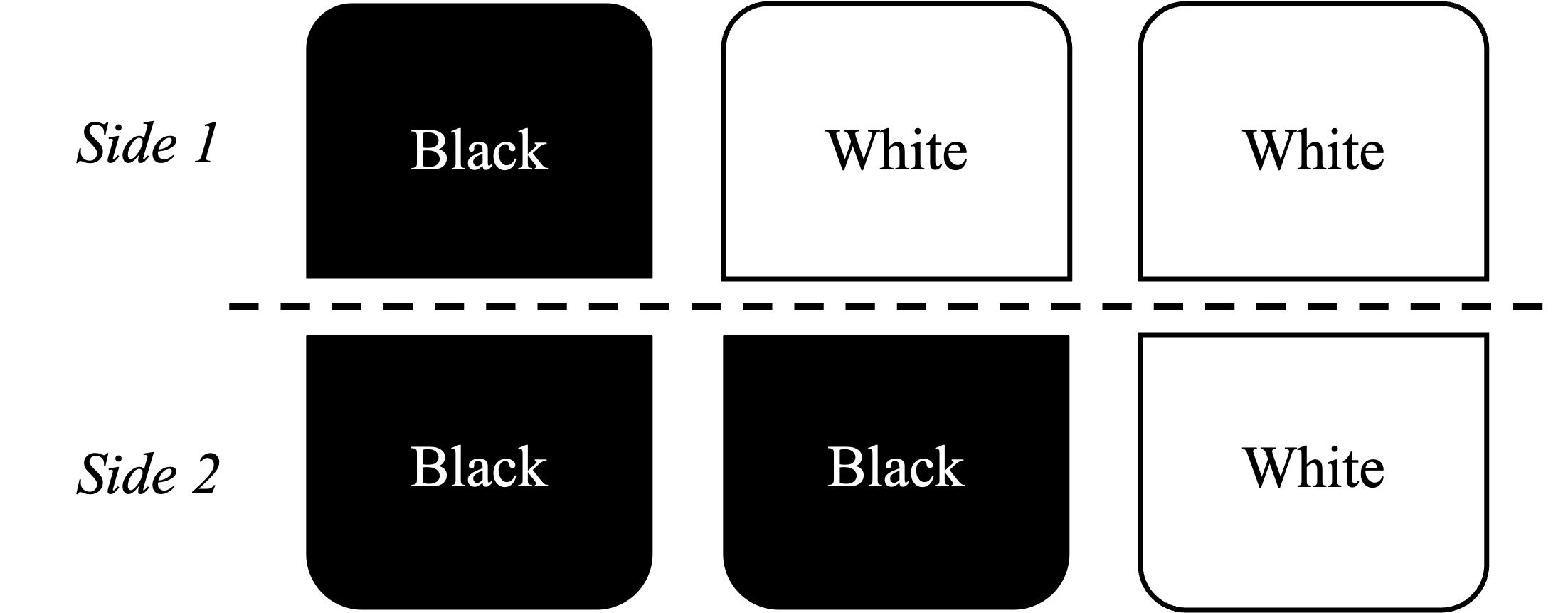
Each of the six sides has the same probability of being picked. There are three equally probable cases in which a white side is picked. In two out of three cases, the card is the white-white card.
This can also be verified using Bayes’ rule:
\[ P(A | B) = \frac{P(B | A)P(A)}{P(B)} \]
Where \(P(A | B)\) is the probability of event \(A\) given event \(B\).
Here, let’s note the events:
- \(A\): the card is white on the other side (it is the white-white card)
- \(B\): the first side of the card is white
We want to know: \(P(A | B)\), probability of \(A\) given \(B\).
Using Bayes’ rule, we get: \[ P(A | B) = \frac{P(B | A)P(A)}{P(B)} \]
Evaluating these one by one:
- \(P(A)\), probability of getting the white-white card: there are three cards, so this probability is \(1/3\)
- \(P(B|A)\), given that the card is white-white, what is the probability of having its first side white? That is \(1\)
- \(P(B)\), probability of getting the first side white, trickier to evaluate:
- Case 1: card is white-white, then this would be a probability \(1\)
- Case 2: card is white-black, then this would be \(1/2\)
- Case 3: card is black-black, then \(0\)
To get the total probability of \(B\), we sum all of these cases:
\[ \begin{aligned} P(B) &= P(B|\text{white-white}) \cdot P(\text{white-white}) + \\ &\quad P(B|\text{black-white}) \cdot P(\text{black-white}) + \\ &\quad P(B|\text{black-black}) \cdot P(\text{black-black}) \end{aligned} \]
\[ P(B) = 1 \cdot \frac{1}{3} + \frac{1}{2} \cdot \frac{1}{3} + 0 \cdot \frac{1}{3} = \frac{1}{3} + \frac{1}{6} = \frac{1}{2} \]
Plugging these values into Bayes’ rule, we get: \[ P(A | B) = \frac{1 \cdot \frac{1}{3}}{\frac{1}{2}} = \frac{2}{3} \]
This goes to show that not all word prediction tasks are created equal. Some words do require more thinking than others.
Similarly, when solving simple multiplication tasks, we can easily predict the next word here:
\(3 \cdot 3 = ?\)
As this is something that has been drilled into us as a child.
But when presented with a tougher multiplication:
\(3 \cdot 97 = ?\)
We probably cannot answer straight away and have to spend time thinking about the result. In this thinking time, we are doing nothing more than creating intermediate words or thoughts in our head to come up with an answer. Presented with an even harder problem, we may find it useful to write these intermediate words on paper.
This argument is nothing groundbreaking. Let’s get back to generative AI models.
Generative AI and next word prediction
Generative AI models can be understood as a very good auto-complete program. Given a sequence of words, they predict the next word. These models use the same amount of computation to predict each next word.
This works well with narrative or declarative text:
I am ?
I am very ?
I am very happy ?
I am very happy today ?
I am very happy today .With such a simple sentence, generating the next word is a relatively straightforward task.
However, as we have seen above, not all next word predictions are equally easy. Some next words require more thinking than others.
Daily Life
This is confirmed by our life experience. When writing a diary entry, or this paragraph, words simply flow from one to the next. Building simple sentences like this is something we learn from a young age. This flow does get interrupted when asked a tough question, or having to solve a maths problem that involves reasoning.
What if we, just like generative AI models, also used the same amount of brain computation to predict the next word? When faced with a tough question, what if we had to generate more words and mobilise more brain computation power to come up with an answer?
Looking into our everyday experience, we can text our friends and our sentences just flow. And yet, when we are presented with a maths problem, we have to think of intermediate steps, to reason.
As an example:
\[ 3 \cdot 97 = 3 \cdot (100 - 3) = 300 - 9 = 291 \]
This seems to be exactly what the latest reasoning models like OpenAI o1 and DeepSeek R1 are trained to do. When asking a question to DeepSeek R1, you can see its reasoning chain, the intermediate tokens that are used to get to the final answer.
When we perform reasoning, we could simply be overcoming the fact that the amount of brain computation we use to predict each next word is fixed. We then introduce additional words between the question and the answer.
This idea baffled me, and showed once more that one of the best ways to understand intelligence is trying to build it.
Or for that matter, one of the best ways to understand anything is trying to build it.
Final Thoughts
Going back from abstraction to our everyday life. What should we make of this? The next time you are faced with a problem you cannot solve directly:
- Make sure you understand the target, the answer expected
- Start from what you know
- From what you know, investigate the different directions you could go by combining what you know
- Follow promising tracks
- If this does not solve it, summarise the outcome of your different reasoning tracks and identify gaps
- Ask for help to fill them in
This is nothing that has not been said before. But somehow, understanding why this method worked changed my view on problem solving.